Matplotlib 超入門
Colaboratory での実行を想定しています。 準備はこちらを参照ください。
Matplotlib
Matplotlib とはデータをグラフ描画する機能を備えたライブラリです。さまざまな形式のグラフやチャートを表現することができます。詳細は 公式ドキュメント を参照してください。ここでは、最小限の説明に留めます。
Anatomy of a figure
matplotlibで描画される図の各部の説明の詳細は こちら を参照してください。 matplotlibでは図の各部についてひとつひとつ設定しながらレイヤーのように重ねて図を作成します。設定詳細については上記の公式ドキュメントを参照してください。ここでは、最低限の描画の仕方の例を提示します。
可視化の雛形
まず、ライブラリをインポートします。
import matplotlib.pyplot as pltアンスコムのデータを可視化します。アンスコムのデータについては pandas 超入門 シリーズで扱っているので、初めての方はこちらをご覧ください。
# アンスコムのデータの読み込み
anscombe = pd.read_json('./sample_data/anscombe.json')まずはすべてのデータ点を可視化してみます。subplot関数を使います。
# 図の全体を作成
fig, ax = plt.subplots()
# 横軸縦軸を与えて、データ点をプロット
ax.plot(anscombe['X'], anscombe['Y'])
# x軸のラベル設定
ax.set_xlabel('X')
# y軸のラベル設定
ax.set_ylabel('Y')
# 図のタイトル設定
ax.set_title('Anscombe Data')
これだとなんだかわからないため、次に Seriesごとにデータを分けてそれぞれを描画してみましょう。複数のプロット領域をレイアウトすることができる、subplots関数を使います。
# データの分割
anscombe_1 = anscombe[anscombe['Series']=='I']
anscombe_2 = anscombe[anscombe['Series']=='II']
anscombe_3 = anscombe[anscombe['Series']=='III']
anscombe_4 = anscombe[anscombe['Series']=='IV']データを分割したらそれぞれを並べて表示させます。
# 図の全体を作成(プロット領域のレイアウトを指定)
fig, axes = plt.subplots(2,2)
# 各プロット領域にデータ点をプロットする
axes[0][0].scatter(anscombe_1['X'], anscombe_1['Y'])
axes[0][1].scatter(anscombe_2['X'], anscombe_2['Y'])
axes[1][0].scatter(anscombe_3['X'], anscombe_3['Y'])
axes[1][1].scatter(anscombe_4['X'], anscombe_4['Y'])
# 各プロットのx軸のラベル設定
axes[0][0].set_xlabel('X')
axes[0][1].set_xlabel('X')
axes[1][0].set_xlabel('X')
axes[1][1].set_xlabel('X')
# 各プロットのy軸のラベル設定
axes[0][0].set_ylabel('Y')
axes[0][1].set_ylabel('Y')
axes[1][0].set_ylabel('Y')
axes[1][1].set_ylabel('Y')
# 各プロット領域のタイトル設定
axes[0][0].set_title('Series=I')
axes[0][1].set_title('Series=II')
axes[1][0].set_title('Series=III')
axes[1][1].set_title('Series=IV')
# 全体のタイトル設定
fig.suptitle('Anscombe Data')
# 余白の調整
fig.tight_layout()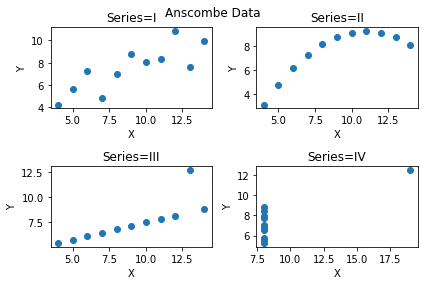
アンスコムのデータはSeriesごとに同じ値の要約統計量でしたが、上記のように全く別の分布をしていることがわかります。もともとこのデータセットは「要約統計量だけに注目すると、ときにデータの理解を誤るおそれがある」という注意を喚起するとともに、統計グラフの可視化の重要性を説くために英国の統計学者 Frank Anscombeが作成したものです。
ここで、figとax(複数形axex)の違いが少し明確になったためイメージを押さえておきましょう。端的に言うとfigは描画する土台となるもので、axは土台にセットする描画物そのものを表しています。複数の描画物を用意する場合にはsubplotsの引数にそのアレンジ(今回の例では2×2で描画物をおくという宣言)の仕方を渡します。
最後に1つのプロット領域でSeriesで区別しながら描画する方法を示します。ふたたび、subplot関数を用います。
# 図の全体を作成
fig, ax = plt.subplots()
# 横軸縦軸を与えて、データ点をプロット
ax.scatter(anscombe_1['X'], anscombe_1['Y'], label='I')
ax.scatter(anscombe_2['X'], anscombe_2['Y'], label='II')
ax.scatter(anscombe_3['X'], anscombe_3['Y'], label='III')
ax.scatter(anscombe_4['X'], anscombe_4['Y'], label='IV')
# x軸のラベル設定
ax.set_xlabel('X')
# y軸のラベル設定
ax.set_ylabel('Y')
# 図のタイトル設定
ax.set_title('Anscombe Data')
# グリッド線の表示
ax.grid(linestyle='--')
# 凡例設定
fig.legend(loc='lower right')
# 余白の調整
fig.tight_layout()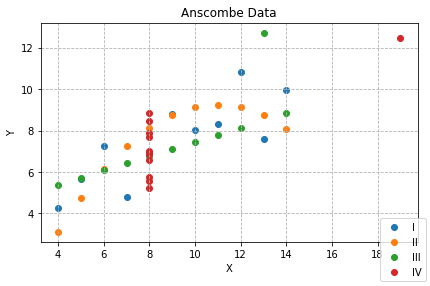
このように1つのプロット領域にすべてのデータを可視化するとかえってデータを捉えにくくなる場合もあります。どのような可視化が最適であるか、ということに注意しながら可視化していく必要があります。